library(targets)
library(tarchetypes)
target <- tar_render(report, "report.Rmd") # Just defines a target definition object.
target$command$expr[[1]]
#> tarchetypes::tar_render_run(path = "report.Rmd", args = list(input = "report.Rmd",
#> knit_root_dir = getwd(), quiet = TRUE), deps = list(fit,
#> hist))12 Literate programming
Literate programming is the practice of mixing code and descriptive writing in order to execute and explain a data analysis simultaneously in the same document. The targets package supports literate programming through tight integration with Quarto, R Markdown, and knitr. It is recommended to learn one of these three tools before proceeding.
12.1 Scope
There are two kinds of literate programming in targets:
- A literate programming source document (or Quarto project) that renders inside an individual target. Here, you define a special kind of target that runs a lightweight R Markdown report or Quarto report/project which depends on upstream targets.
- The
tar_tangle()function available intarchetypes>= 0.13.2.9002, which lets you express the pipeline itself as a Quarto or R Markdown document.
This chapter focuses on (1), which is more ubiquitous and versatile.
12.2 R Markdown targets
Here, literate programming serves to display, summarize, and annotate results from upstream in the targets pipeline. The document(s) have little to no computation of their own, and they make heavy use of tar_read() and tar_load() to leverage output from other targets.
As an example, let us extend the walkthrough example chapter with the following R Markdown source file report.Rmd.
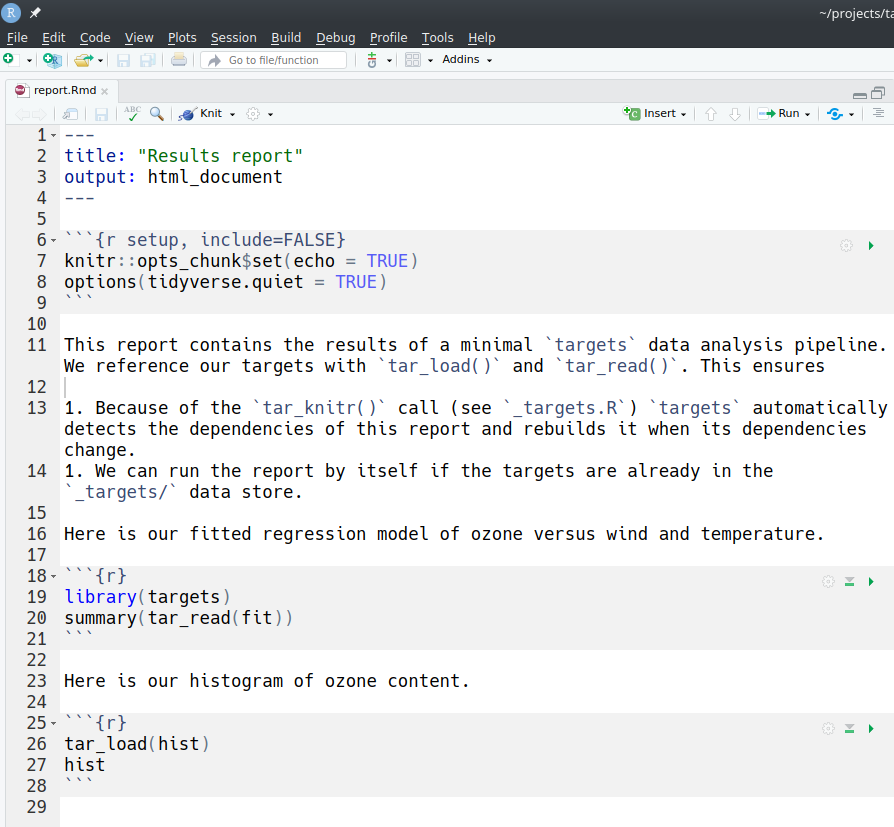
This document depends on targets fit and hist. If we previously ran the pipeline and the data store _targets/ exists, then tar_read() and tar_load() will read those targets and show them in the rendered HTML output report.html.
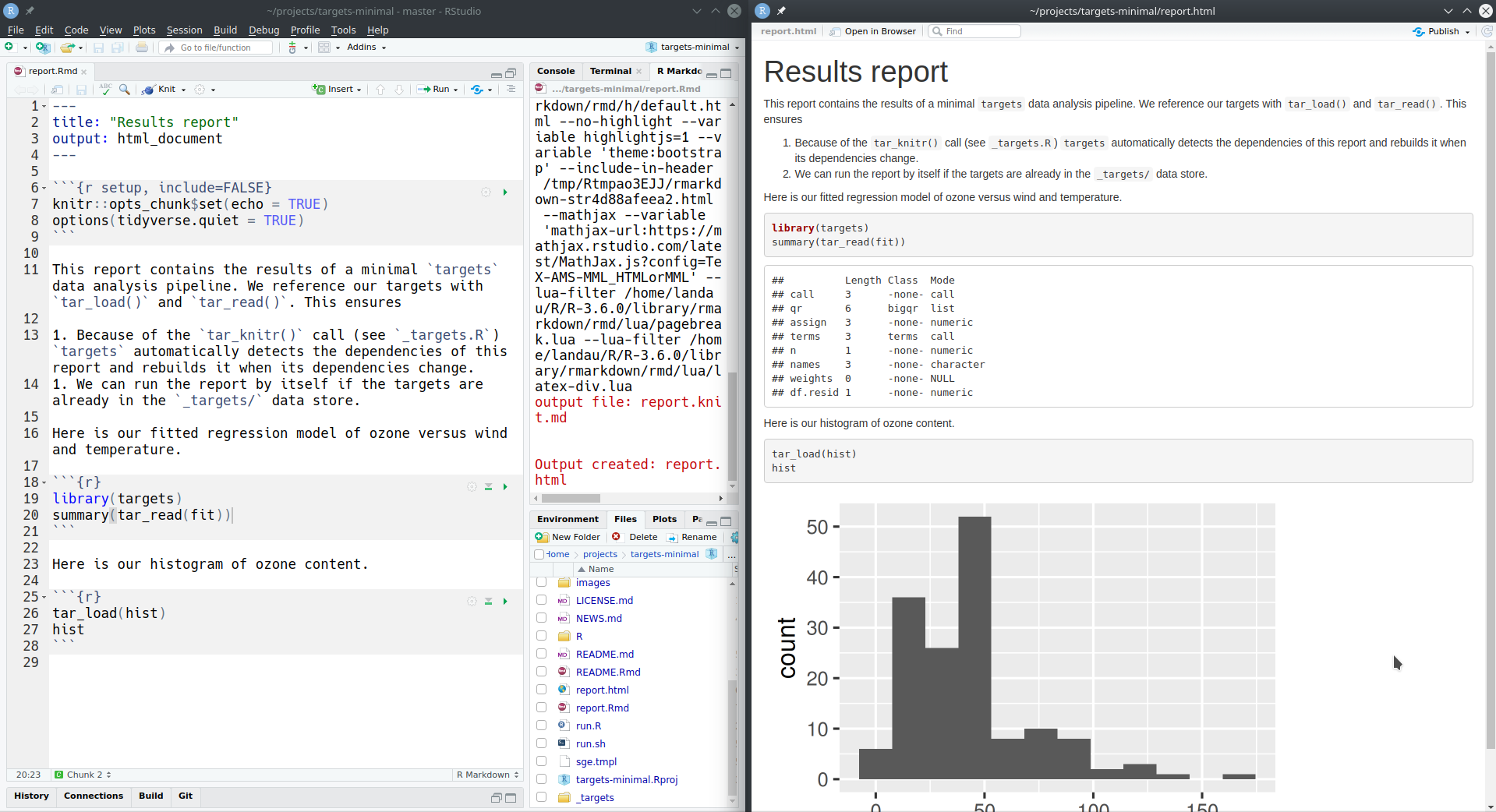
With the tar_render() function in tarchetypes, we can go a step further and include report.Rmd as a target in the pipeline. This new targets re-renders report.Rmd whenever fit or hist changes, which means tar_make() brings the output file report.html up to date.
tar_render() is like tar_target(), except that you supply the file path to the R Markdown report instead of an R command. Here it is at the bottom of the example _targets.R file below:
# _targets.R
library(targets)
library(tarchetypes)
source("R/functions.R")
list(
tar_target(
raw_data_file,
"data/raw_data.csv",
format = "file"
),
tar_target(
raw_data,
read_csv(raw_data_file, col_types = cols())
),
tar_target(
data,
raw_data %>%
mutate(Ozone = replace_na(Ozone, mean(Ozone, na.rm = TRUE)))
),
tar_target(hist, create_plot(data)),
tar_target(fit, biglm(Ozone ~ Wind + Temp, data)),
tar_render(report, "report.Rmd") # Here is our call to tar_render().
)When we visualize the pipeline, we see that our report target depends on targets fit and hist. tar_render() automatically detects these upstream dependencies by statically analyzing report.Rmd for calls to tar_load() and tar_read().
# R console
tar_visnetwork()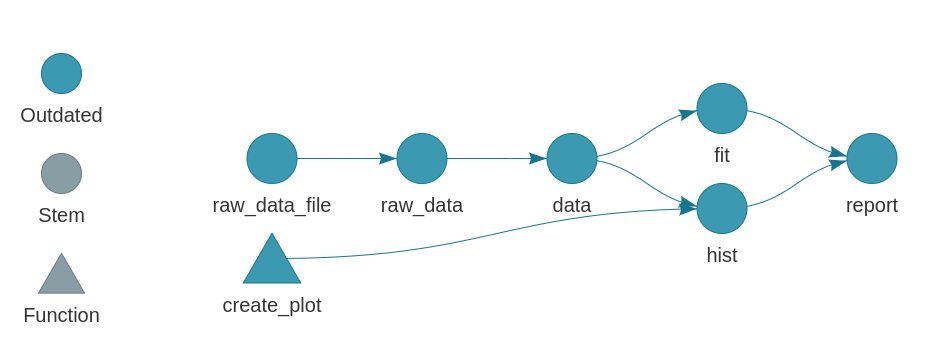
12.3 Quarto targets
tarchetypes >= 0.6.0.9000 supports a tar_quarto() function, which is like tar_render(), but for Quarto. For an individual source document, tar_quarto() works exactly the same way as tar_render(). However, tar_quarto() is more powerful: you can supply the path to an entire Quarto project, such as a book, blog, or website. tar_quarto() looks for target dependencies in all the source documents (e.g. listed in _quarto.yml), and it tracks the important files in the project for changes (run tar_quarto_files() to see which ones).
12.4 Parameterized documents
tarchetypes functions make it straightforward to use parameterized R Markdown and parameterized Quarto in a targets pipeline. The next two subsections walk through the major use cases.
12.5 Single parameter set
In this scenario, the pipeline renders your parameterized report one time using a single set of parameters. These parameters can be upstream targets, global objects, or fixed values. Simply pass a params argument to tar_render() or an execute_params argument to tar_quarto(). Example:
# _targets.R
library(targets)
library(tarchetypes)
list(
tar_target(data, data.frame(x = seq_len(26), y = letters))
tar_quarto(report, "report.qmd", execute_params = list(your_param = data))
)Internally, the report target runs:
# R console
quarto::quarto_render("report.qmd", params = list(your_param = your_target))where report.qmd looks like this:
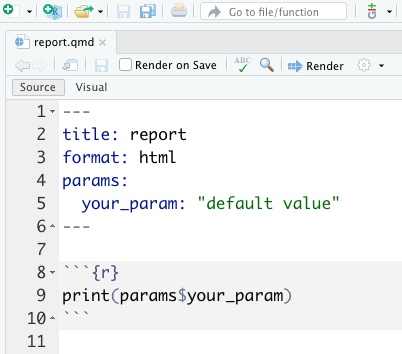
See tar_quarto() examples and tar_render() examples for more.
12.6 Multiple parameter sets
In this scenario, you still have a single report, but you render it multiple times over a grid of parameters. This time, use tar_quarto_rep() or tar_render_rep(). Each of these functions takes as input a grid of parameters with one column per parameter and one row per parameter set, where each parameter set is used to render an instance of the document. In other words, the number of rows in the parameter grid is the number of output documents you will produce. Below is an example _targets.R file using tar_render_rep(). Usage with tar_quarto_rep() is the same1.
# _targets.R
library(targets)
library(tarchetypes)
tar_option_set(packages = "tibble")
list(
tar_target(x, "value_of_x"),
tar_render_rep(
report,
"report.Rmd",
execute_params = tibble(
your_param = c("par_val_1", "par_val_2", "par_val_3", "par_val_4"),
output_file = c("f1.html", "f2.html", "f3.html", "f4.html")
),
batches = 2
)
)where report.Rmd has the following YAML front matter:
title: report
output_format: html_document
params:
par: "default value"and the following R code chunk:
print(params$par)
print(tar_read(x))tar_render_rep() creates a target for the parameter grid and uses dynamic branching to render the output reports in batches. In this case, we have two batches (dynamic branches) that each produce two reports (four output reports total).
# R console
tar_make()
#> + x dispatched
#> ✔ x completed [3ms, 62 B]
#> + report_params dispatched
#> ✔ report_params completed [2ms, 204 B]
#> + report declared [2 branches]
#> ✔ report completed [8.4s, 1.81 MB]
#> ✔ ended pipeline [8.6s, 4 completed, 0 skipped] The third output file f3.html is below, and the rest look similar.

For more information, see these examples.
except the parameter grid argument is called
execute_paramsintar_quarto_rep().↩︎