# _targets.R
tar_option_set(resources = list(bucket = "my-bucket-name"))
list(
tar_target(dataset, get_large_dataset(), format = "aws_fst_tbl"),
tar_target(analysis, analyze_dataset(dataset), format = "aws_qs")
)Appendix B — What about drake?
![]()
targets is the successor of drake, an older pipeline tool. As of 2021-01-21, drake is superseded, which means there are no plans for new features or discretionary enhancements, but basic maintenance and support will continue indefinitely. Existing projects that use drake can safely continue to use drake, and there is no need to retrofit targets. New projects should use targets because it is friendlier and more robust.
B.1 Why is drake superseded?
Nearly four years of community feedback have exposed major user-side limitations regarding data management, collaboration, dynamic branching, and parallel efficiency. Unfortunately, these limitations are permanent. Solutions in drake itself would make the package incompatible with existing projects that use it, and the internal architecture is too copious, elaborate, and mature for such extreme refactoring. That is why targets was created. The targets package borrows from past learnings, user suggestions, discussions, complaints, success stories, and feature requests, and it improves the user experience in ways that will never be possible in drake.
B.2 Transitioning to targets
If you know drake, then you already almost know targets. The programming style is similar, and most functions in targets have counterparts in drake.
Likewise, many make() arguments have equivalent arguments elsewhere.
Argument of drake::make() |
Counterparts in targets |
|---|---|
targets |
names in tar_make() etc. |
envir |
envir in tar_option_set() |
verbose |
reporter in tar_make() etc. |
parallelism |
Choice of function: tar_make() vs tar_make_clustermq() vs tar_make_future() |
jobs |
workers in tar_make_clustermq() and tar_make_future() |
packages |
packages in tar_target() and tar_option_set() |
lib_loc |
library in tar_target() and tar_option_set() |
trigger |
cue in tar_target() and tar_option_set() |
caching |
storage and retrieval in tar_target() and tar_option_set() |
keep_going |
error in tar_target() and tar_option_set() |
memory_strategy |
memory in tar_target() and tar_option_set() |
garbage_collection |
garbage_collection in tar_target() and tar_option_set() |
template |
resources in tar_target() and tar_option_set(), along with helpers like tar_resources(). |
curl_handles |
handle element of resources argument of tar_target() and tar_option_set() |
format |
format in tar_target() and tar_option_set() |
seed |
Superfluous because targets always uses the same global seed. [tar_meta()] shows all the target-level seeds. |
In addition, many optional columns of drake plans are expressed differently in targets.
Optional column of drake plans |
Feature in targets |
|---|---|
format |
format argument of tar_target() and tar_option_set() |
dynamic |
pattern argument of tar_target() and tar_option_set() |
transform |
static branching functions in tarchetypes such as tar_map() and tar_combine() |
trigger |
cue argument of tar_target() and tar_option_set() |
hpc |
deployment argument of tar_target() and tar_option_set() |
resources |
resources argument of tar_target() and tar_option_set() |
caching |
storage and retrieval arguments of tar_target() and tar_option_set() |
B.3 Advantages of targets over drake
B.3.1 Better guardrails by design
drake leaves ample room for user-side mistakes, and some of these mistakes require extra awareness or advanced knowledge of R to consistently avoid. The example behaviors below are too systemic to solve and still preserve back-compatibility.
- By default,
make()looks for functions and global objects in the parent environment of the calling R session. Because the global environment is often old and stale in practical situations, which causes targets to become incorrectly invalidated. Users need to remember to restart the session before callingmake(). The issue is discussed here, and the discussion led to functions liker_make()which always create a fresh session to do the work. However,r_make()is not a complete replacement formake(), and beginner users still run into the original problems. - Similar to the above,
make()does not find the intended functions and global objects if it is called in a different environment. Edge cases like this one and this one continue to surprise users. drakeis extremely flexible about the location of the.drake/cache. When a user callsreadd(),loadd(),make(), and similar functions,drakesearches up through the parent directories until it finds a.drake/folder. This flexibility seldom helps, and it creates uncertainty and inconsistency when it comes to initializing and accessing projects, especially if there are multiple projects with nested file systems.
The targets package solves all these issues by design. Functions tar_make(), tar_make_clustermq(), and tar_make_future() all create fresh new R sessions by default. They all require a _targets.R configuration file in the project root (working directory of the tar_make() call) so that the functions, global objects, and settings are all populated in the exact same way each session, leading to less frustration, greater consistency, and greater reproducibility. In addition, the _targets/ data store always lives in the project root.
B.3.2 Enhanced debugging support
targets has enhanced debugging support. With the workspaces argument to tar_option_set(), users can locally recreate the conditions under which a target runs. This includes packages, global functions and objects, and the random number generator seed. Similarly, tar_option_set(error = "workspace") automatically saves debugging workspaces for targets that encounter errors. The debug option lets users enter an interactive debugger for a given target while the pipeline is running. And unlike drake, all debugging features are fully compatible with dynamic branching.
B.3.3 Improved tracking of package functions
By default, targets ignores changes to functions inside external packages. However, if a workflow centers on a custom package with methodology under development, users can make targets automatically watch the package’s functions for changes. Simply supply the names of the relevant packages to the imports argument of tar_option_set(). Unlike drake, targets can track multiple packages this way, and the internal mechanism is much safer.
B.3.4 Lighter, friendlier data management
drake’s cache is an intricate file system in a hidden .drake folder. It contains multiple files for each target, and those names are not informative. (See the files in the data/ folder in the diagram below.) Users often have trouble understanding how drake manages data, resolving problems when files are corrupted, placing the data under version control, collaborating with others on the same pipeline, and clearing out superfluous data when the cache grows large in storage.
.drake/
├── config/
├── data/
├───── 17bfcef645301416.rds
├───── 21935c86f12692e2.rds
├───── 37caf5df2892cfc4.rds
├───── ...
├── drake/
├───── history/
├───── return/
├───── tmp/
├── keys/ # A surprisingly large number of tiny text files live here.
├───── memoize/
├───── meta/
├───── objects/
├───── progress/
├───── recover/
├───── session/
└── scratch/ # This folder should be temporary, but it gets egregiously large.The targets takes a friendlier, more transparent, less mysterious approach to data management. Its data store is a visible _targets folder, and it contains far fewer files: a spreadsheet of metadata, a spreadsheet of target progress, and one informatively named data file for each target. It is much easier to understand the data management process, identify and diagnose problems, place projects under version control, and avoid consuming unnecessary storage resources. Sketch:
_targets/
├── meta/
├───── meta
├───── process
├───── progress
├── objects/
├───── target_name_1
├───── target_name_2
├───── target_name_3
├───── ...
├── scratch/ # tar_make() deletes this folder after it finishes.
└── user/ # gittargets users can put custom files here for data version control.B.3.5 Cloud storage
Thanks to the simplified data store and simplified internals, targets can automatically upload data to the Amazon S3 bucket of your choice. Simply configure aws.s3, create a bucket, and select one of the AWS-powered storage formats. Then, targets will automatically upload the return values to the cloud.
Data retrieval is still super easy.
tar_read(dataset)B.3.6 Show status of functions and global objects
drake has several utilities that inform users which targets are up to date and which need to rerun. However, those utilities are limited by how drake manages functions and other global objects. Whenever drake inspects globals, it stores their values in its cache and loses track of their previous state from the last run of the pipeline. As a result, it has trouble informing users exactly why a given target is out of date. And because the system for tracking global objects is tightly coupled with the cache, this limitation is permanent.
In targets, the metadata management system only updates information on global objects when the pipeline actually runs. This makes it possible to understand which specific changes to your code could have invalided your targets. In large projects with long runtimes, this feature contributes significantly to reproducibility and peace of mind.
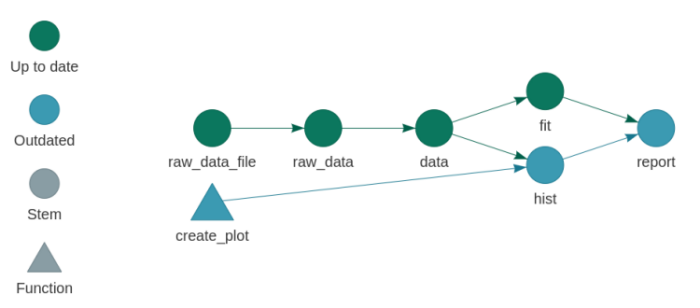
B.3.7 Dynamic branching with dplyr::group_by()
Dynamic branching was an architecturally difficult fit in drake, and it can only support one single (vctrs-based) method of slicing and aggregation for processing sub-targets. This limitation has frustrated members of the community, as discussed here and here.
targets, on the other hand, is more flexible regarding slicing and aggregation. When it branches over an object, it can iterate over vectors, lists, and even data frames grouped with dplyr::group_by(). To branch over chunks of a data frame, our data frame target needs to have a special tar_group column. We can create this column in our target’s return value with the tar_group() function.
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(targets)
library(tarchetypes)
library(tibble)
tibble(
x = seq_len(6),
id = rep(letters[seq_len(3)], each = 2)
) %>%
group_by(id) %>%
tar_group()
#> # A tibble: 6 × 3
#> x id tar_group
#> <int> <chr> <int>
#> 1 1 a 1
#> 2 2 a 1
#> 3 3 b 2
#> 4 4 b 2
#> 5 5 c 3
#> 6 6 c 3Our actual target has the command above and iteration = "group".
tar_target(
data,
tibble(
x = seq_len(6),
id = rep(letters[seq_len(3)], each = 2)
) %>%
group_by(id) %>%
tar_group(),
iteration = "group"
)Now, any target that maps over data is going to define one branch for each group in the data frame. The following target creates three branches when run in a pipeline: one returning 3, one returning 7, and one returning 11.
tar_target(
sums,
sum(data$x),
pattern = map(data)
)B.3.8 Composable dynamic branching
Because the design of targets is fundamentally dynamic, users can create complicated dynamic branching patterns that are never going to be possible in drake. Below, target z creates six branches, one for each combination of w and tuple (x, y). The pattern cross(w, map(x, y)) is equivalent to tidyr::crossing(w, tidyr::nesting(x, y)).
# _targets.R
library(targets)
library(tarchetypes)
list(
tar_target(w, seq_len(2)),
tar_target(x, head(letters, 3)),
tar_target(y, head(LETTERS, 3)),
tar_target(
z,
data.frame(w = w, x = x, y = y),
pattern = cross(w, map(x, y))
)
)B.3.9 Improved parallel efficiency
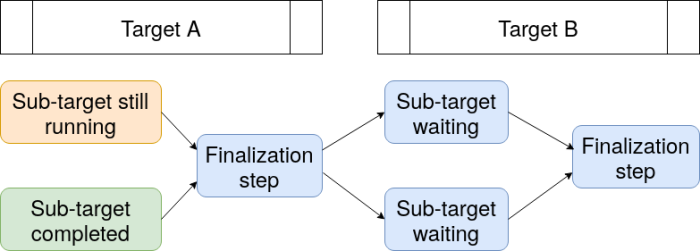
Dynamic branching in drake is staged. In other words, all the sub-targets of a dynamic target must complete before the pipeline moves on to downstream targets. The diagram below illustrates this behavior in a pipeline with a dynamic target B that maps over another dynamic target A. For thousands of dynamic sub-targets with highly variable runtimes, this behavior consumes unnecessary runtime and computing resources. And because drake’s architecture was designed at a fundamental level for static branching only, this limitation is permanent.
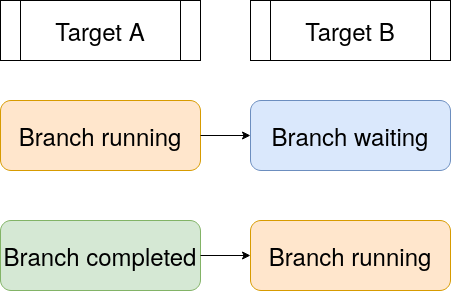
By contrast, the internal data structures in targets are dynamic by design, which allows for a dynamic branching model with more flexibility and parallel efficiency. Branches can always start as soon as their upstream dependencies complete, even if some of those upstream dependencies are branches. This behavior reduces runtime and reduces consumption of computing resources.
B.3.10 Metaprogramming
In drake, pipelines are defined with the drake_plan() function. drake_plan() supports an elaborate domain specific language that diffuses user-supplied R expressions. This makes it convenient to assign commands to targets in the vast majority of cases, but it also obstructs custom metaprogramming by users (example here). Granted, it is possible to completely circumvent drake_plan() and create the whole data frame from scratch, but this is hardly ideal and seldom done in practice.
The targets package tries to make customization easier. Relative to drake, targets takes a decentralized approach to setting up pipelines, moving as much custom configuration as possible to the target level rather than the whole pipeline level. In addition, the tar_target_raw() function avoids non-standard evaluation while mirroring tar_target() in all other respects. All this makes it much easier to create custom metaprogrammed pipelines and target archetypes while avoiding an elaborate domain specific language for static branching, which was extremely difficult to understand and error prone in drake. The R Targetopia is an emerging ecosystem of workflow frameworks that take full advantage of this customization and democratize reproducible pipelines.